Anomalies: un-asking the question
Has the dog Buddha-nature? MU!
Most of the time, when we work on binary classifiers, we require that they give a yes-or-no answer to every question. But there are some real-world situations where we might like to allow a classifier to say “I don’t know”, or even “I don’t think that question quite makes sense”.
One classic classifier is the Altman Z-score, used in analysing whether companies are at risk of bankruptcy. Here, we have a discriminant value which is a linear combination of the variables. Instead of a single threshold on the discriminant value, giving two classes, Altman set two thresholds, giving three classes. They were the “Safe Zone”, “Gray Zone”, and “Distress Zone”. In other words, when the discriminant took on an intermediate value, the classifier refused to answer. He could have set a single boundary instead, giving “Safe” or “Distress” for every query, but would have got more incorrect predictions. Putting in a large “Gray Zone” is a conservative approach.
In a lot of real-world examples, it’s better for the classifier to be conservative in this way. In a medical diagnosis scenario, clearly it would be better for the classifier to say “I don’t know” when it really doesn’t, and effectively turn the case over to a human expert.
A really nice recent blog post by Kruchten goes into detail on another scenario in which a refusal to answer can lead to better outcomes, even though calling the human expert comes at a cost, because both false positives and false negatives have their own costs. In effect, we can use the classifier as a cheap way of catching the easy cases, and use the more expensive human expertise to get higher accuracy on the difficult cases (all this is assuming that a human expert actually is capable of higher accuracy on difficult cases, of course).
The same blog post points to a JMLR paper by Bartlett and Wegkamp. Here, we are again using a discriminant function $f(x)$, with zero as the threshold. However, if $|f(x)| < \delta$, the classifier refuses to answer.
Separately, Richard Forsyth, when we met at EuroGP 2016, was proposing the idea that every classifier should be allowed to say “this example is nothing like what I’ve seen before, so I don’t want to classify it”. Now even though this again leads to a refusal to classify – just like in Bartlett’s paper – this is really a different issue. Consider the following figure. Which of the query points – the green triangles – do we feel more confident about?
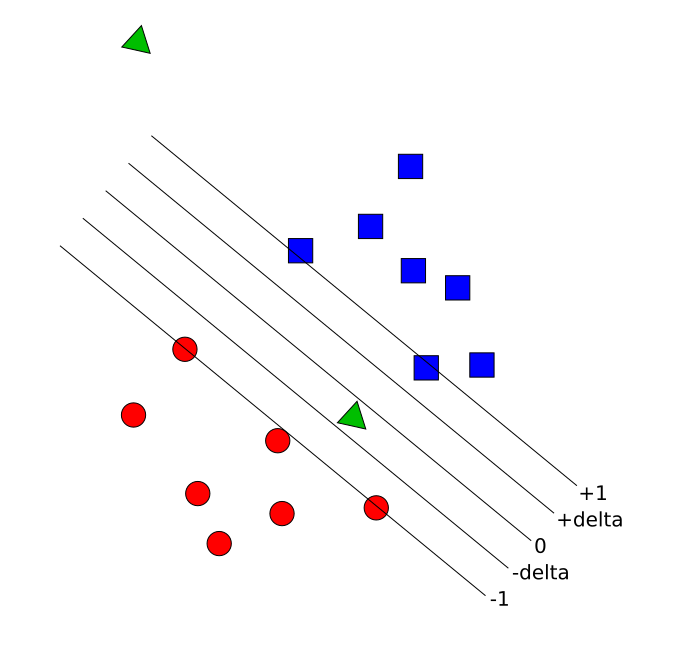
What we’re seeing here is two completely different types of uncertainty. There are points which are “between” the two classes observed in training data, where our confidence in the correct class label is low. And there are points from far away, where we’re not even confident that the point comes from either class, or that there hasn’t been some kind of error when inputting the data. Maybe both types of uncertainty should lead to our classifier asking for human intervention.
We can implement all this using an anomaly detection system as a first pass, which flags any really weird points, followed by a binary classifier with a confidence threshold as in Bartlett and Wegkamp. It would be interesting to look at outliers in some real-world datasets to understand the prevalence of the two types of uncertainty, and hence to carry out the type of economic analysis being carried out by Kruchten.
All of this hooks into an interesting line of research being carried out by my former colleague, Kalyan Veeramachaneni and his start-up company PatternEx. In a recent paper, human expertise is again being called on to decide cases the machine is not yet capable of deciding. This is online learning. The nice thing about it is that the human expert is not called on to label huge amounts of data upfront, but only to decide a small number of selected cases each day. This number can even diminish over time as the model learns.